Yayyy, the continuation of "Things I've Learned" series. Now, I'll also included all my small side projects that I've done recently in this series too so I have something to regularly write on.
Medias Backup Script
So on my Thing I've Learned 1 blog, I have an idea for doing a backup script for all blog medias. I've already implemented it, and on this blog I'll describe how it work.
The script is just a simple ~150 lines of Go code with a few standard libraries. How it work is pretty straight forward too. For each blog we do
- We gather all medias link from the blog markdown file by using Go regex and also check if it's
a valid URL.
<img\s+[^>]*src="([^"]+)" // for <img src="..."/> <source\s+[^>]*src="([^"]+)" // for <source src="..." /> !\[.*?\]\(([^\)]+) // for markdown  - Download all medias in it via
HTTP GETrequest, this step is the most problemetic step because I've used imgur to host some images and it just always throw429to me. As I go through what is the differences between my GET request on the browser and my script, I found out that Gohttplibrary does not setUser-Agentheader and imgur need it, so the problem is solved. (This tooks me like 2 hour to figured it out 🤦♂️) - Just write the files to a specific backup folder, the interesting part in this step would be that
Go
os.MkdirAllandos.WriteFileboth require the unix permission code which I specify0766for a directory and0644for a file. You may notice the leading zero, and wonder why we need it? So in Go a literal with leading zero is octal number meaning0777 = 0b 111 111 111.
Note: The unix file permission can be break down to this
// own -> owner
// gro -> group
// oth -> others
| own | gro | oth |
d | rwx | r-x | r-x |
- | rw- | r-- | r-- |
// 1 bit most significant bit and 9 least significant bits
d | rwx | rwx | rwx |
S3-Imgur (kind of)
This idea comes from the previous Thing I've Learned too. So, instead of using AWS root account to upload a media for my blog I implement a basic interface for managing medias using S3 as a data store. Actually, it's just a simple CMS that is implenmented by using Go, templ and HTMX which I have want to try for so long. (This repoitory help me so much while I'm developing)
How does it work?
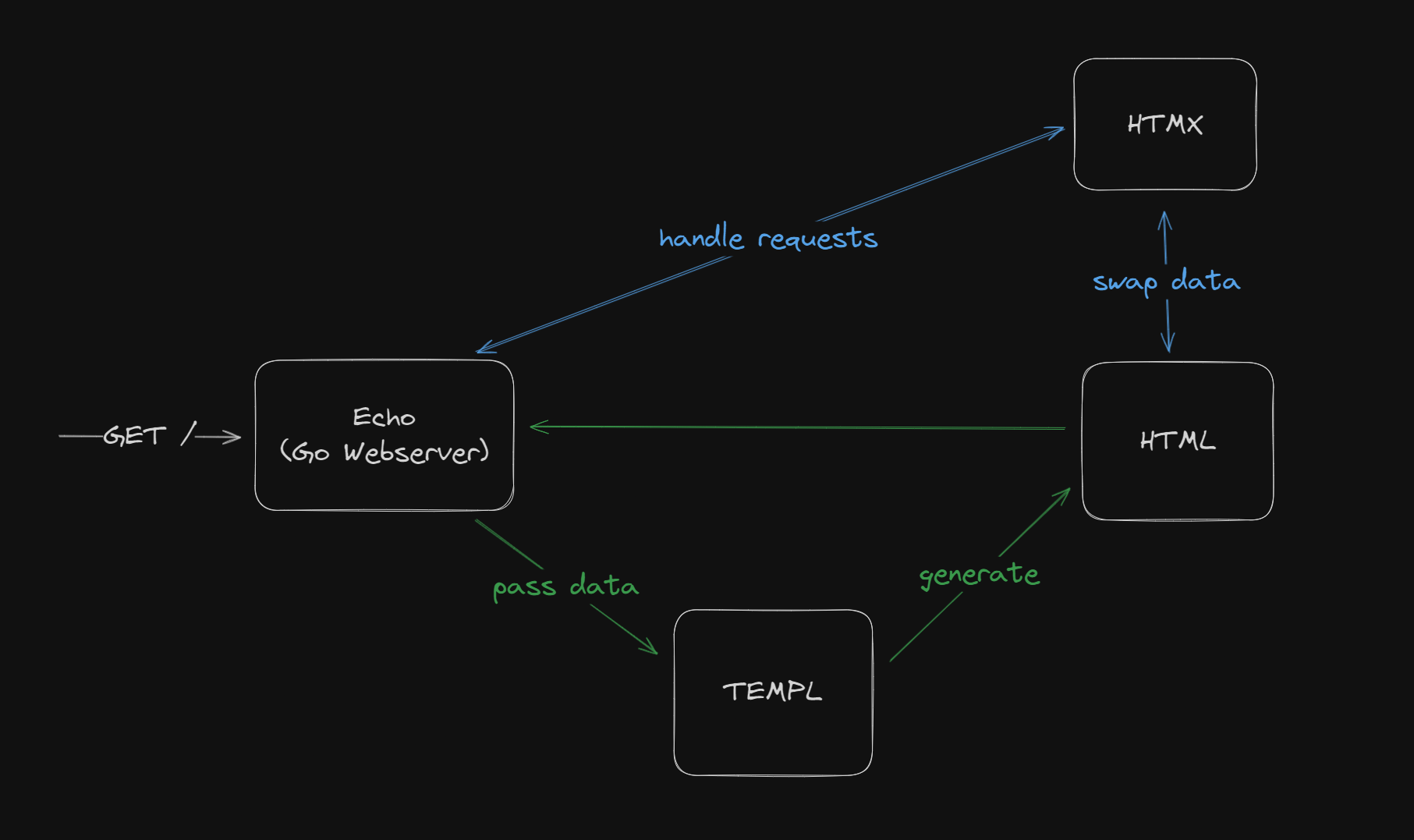
GET / work.The s3-imgur is just a simple web server developed using Echo
that will return a HTML when there's a request to it. For example when we GET /
- Check if we have
/route register or not, if not return404 - Pass the necessary data to templ to generate the HTML that will
be returned. (This is similar to SvelteKit data loading)
templ is a tool for building HTML with Go, it's similar to JSX in React but not exactly the same.
- For interactivity inside the HTML, we use HTMX and some JavaScript. HTMX will handle all
of fetching and reactivity after the fetch e.g. when you add a new folder, the folder list need to
be updated we can do something like
htmlWhen we submit this form and got<form hx-post="/" hx-target="#folderList"> ... </form>200, HTMX will replace the element with idfolderListwith the returned response. You can see that it is pretty similar how we fetch data in React, when we fetch data in React we need to update some states and React will handle the re-render but in HTMX we don't need to handle any client states. (if we don't need it :D)
Yep, that's it. The S3 usage is also simple, we can simulate the folder structure by adding a
prefix to the filename e.g. we have pic.png in folder others, this will be save in S3 as
others--pic.png. I also implemented basic caching for s3 query so we do not need to always
query s3 bucket by saving the necessary data on Go map.
If anyone want to try this, at the time of writing AWS free tier will be enough for everything so you can
- Setup AWS account, Create a new S3 bucket, Setup Cloudfront for that bucket, Setup IAM for that S3 (You can google for these, there should be plenty of resources on the internet).
- Download or store the credentials of the IAM accouont that you have created.
- Clone my repository and then
cd scripts/s3-imgur && go build main.go - Create a new
.envfile that has the same format asexample.envand specify those environment variables. - Run the binary and start interacting with the application.
Lineman Wongnai Interview
Last week, I also have a chance to get interviewd by Lineman Wongnai head of engineer of POS team (P'Sharp). And there are 2 interesting questions that I want to share.
Q1 How to deploy a new release with no down time?
So, I need to answer this question as a developer in details about what steps I need to take. My idea at the interview time, is Rolling Deployment. I don't remember the exact details of my answer so I'll try to answer it again here.
First, I think we need to have a redundancy for that service like having 3 programs that do the same thing but running in different machine, we can do this in Kubernetes by making it a pod. And then we need an API Gateway / Load Balancer to handle all traffics that will go through that service. (I give NGINX as an example)
Now, when we're doing the deployment we can just patch each pod and gradually route request for new release to that pod. Then we can shutdown remaining old pods. Now, that I write it down I think there are some problems that I can think of e.g. how do we know which request is for new release? how about roll back, how should we do it?
Let's continue, don't think about those problems yet. The interviewer then ask me how do we update the NGINX?. Yep, I'm stunned and thinking like ugh how do we do this? And I ask for a hint then he tell me "DNS" and I like yes we can update the DNS record and prepared a new NGINX to wait for DNS update to finished.
After the interview, I also look out for more ideas and I found thie video super useful.
Q2 How to update the API to support new data on existing field with no down time?
The question is similar to previous questions, but with details on database, deployment order, how should we do this with others? and there're million of users using it how to make sure that it has no downtime? (I think it's look like those questions, I'm not too sure lol)
My answer looks like this
- If we need to change a schema in database, the database need to have version field so we know what version of the document we are reading.
- If we need to migrate the database, we will do rolling migration by gradually updating the document in database to matched new requirements.
- When developing a new API, maybe we can add a flag to tell that this is a reqeust for new data so we can keep backward compatibility.
And then the interviewer ask me another question. "What happend when the old API read old data? The update need to be reflected on the user right now." I then answer "I think we can just update the document when reading the old data from our API, but make sure that the behavior of the API is not changed"
And then he tell me to summarize all of this and tell the order of deployment which I messed up lol The deploy steps should be
- Deploy the application code first.
- Migrate the database.
- Remaining things
I told him we need to migrate the database first 🤦♂️ which is wrong because the old code can break when they're reading new database schema.
When I'm writing this I think I structured the answer much better than the time that I got interviewed. So maybe for next interview, write it down first and then tell the story of it.
Some remarks, I think I'll be able to answer all of these questions better if I have a real experience solving these problems. Yeah, long experiences of work definitely sold better than new graduate like me 🗿.
What's next for me?
I'm still unemployed at the time of writing, I hope I got an interesting job soon. If you're interested in me, feels free to contact me via my email ttangun1@gmail.com